[R] InetRead n'affiche pas la source html en entier!
Posté : jeu. 30 juil. 2015 01:15
Bonjour.
Je suis en train de m'écrire une sorte de 'web-grabber' qui collecte les infos des sites qui m'intéressent pour me les envoyer tous les matins par mail.
Globalement cela fonctionne, mais j'ai un souci.
Voici l'exemple (d'aujourd'hui, mais réproductible à n'importe quelle moment avec tous les articles):
http://www.ledauphine.com/isere-nord
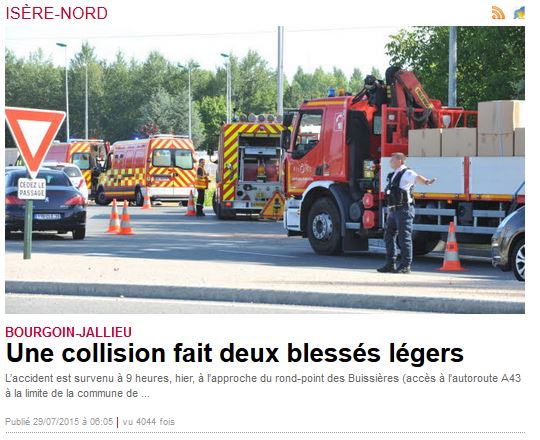
Ce qui m'intéresse c'est le titre, la photo, le petit texte 'gratuite', et la date.
La source sous IE, Firefox ou encore chrome de cette page me donne pour cette section:
Parfait! Tous les infos qui m'intéressent y sont.
-> L'image: <img src="http://s-www.ledauphine.com/images/6D0A ... legers.jpg" alt="Une collision fait deux blessés légers" />
-> Le titre: alt="Une collision fait deux blessés légers" />
-> Le texte: <p>L’accident est survenu à 9 heures, hier, à l’approche du rond-point des Buissières (accès à l’autoroute A43 à la limite de la commune de ... </p> </div>
-> Et la date: <span>Publié </span> 29/07/2015 à 06:05</li>
Théoriquement quelques _ArraySearch & StringSplit et encore un StringLeft/StringRight et l'affaire est clos!
SAUF QUE:
Avec le script suivant:
PS: L'AJOUT DE : HttpSetUserAgent("MyUserAgent") NE CHANGE SRICTEMENT RIEN!!!
J'obtiens:
Tout y est SAUF: <div class="contenu"> ce qui devient <div class="contentInfo"> sans les infos ???
Alors que les scripts 'beaucoup plus lents!!!':
ou encore:
me donnent le résultat:
Sauf que cette fois-ci les infos sur le lien du photo manquent... 
Certes, je pourrais pour contourner mon problème en exécutant les deux scripts pour paralléliser les résultats pour obtenir la totalité des infos souhaitées, mais cela me semble pas trop propre.
Du coup je suis preneur de toute idées pour contourner ce problème d'une manière plus smart..
Amicodement...
Je suis en train de m'écrire une sorte de 'web-grabber' qui collecte les infos des sites qui m'intéressent pour me les envoyer tous les matins par mail.
Globalement cela fonctionne, mais j'ai un souci.
Voici l'exemple (d'aujourd'hui, mais réproductible à n'importe quelle moment avec tous les articles):
http://www.ledauphine.com/isere-nord
Ce qui m'intéresse c'est le titre, la photo, le petit texte 'gratuite', et la date.
La source sous IE, Firefox ou encore chrome de cette page me donne pour cette section:
► Afficher le texte
-> L'image: <img src="http://s-www.ledauphine.com/images/6D0A ... legers.jpg" alt="Une collision fait deux blessés légers" />
{kind=link}
-> Le titre: alt="Une collision fait deux blessés légers" />
-> Le texte: <p>L’accident est survenu à 9 heures, hier, à l’approche du rond-point des Buissières (accès à l’autoroute A43 à la limite de la commune de ... </p> </div>
-> Et la date: <span>Publié </span> 29/07/2015 à 06:05</li>
Théoriquement quelques _ArraySearch & StringSplit et encore un StringLeft/StringRight et l'affaire est clos!
SAUF QUE:
Avec le script suivant:
► Afficher le texte
J'obtiens:
► Afficher le texte
Alors que les scripts 'beaucoup plus lents!!!':
► Afficher le texte
► Afficher le texte
► Afficher le texte
Certes, je pourrais pour contourner mon problème en exécutant les deux scripts pour paralléliser les résultats pour obtenir la totalité des infos souhaitées, mais cela me semble pas trop propre.
Du coup je suis preneur de toute idées pour contourner ce problème d'une manière plus smart..
Amicodement...